Computational Social Science in Public Policy
Brandt School Life
,
Research and PhD
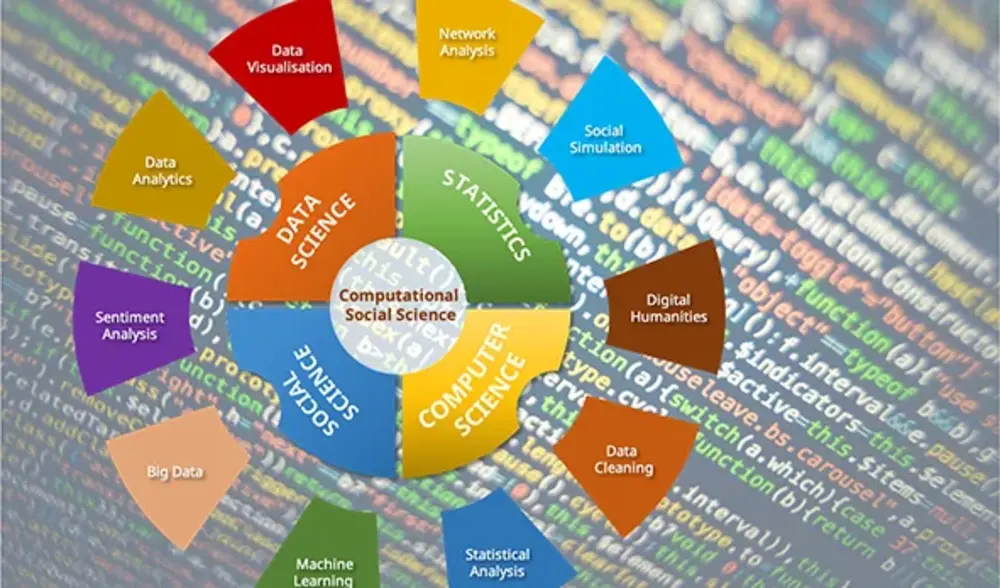
Since the Summer Semester of 2023/24, students at the Willy Brandt School of Public Policy have been experiencing the transformative potential of computational social science through a series of courses on Data Analytics. This initiative aims to equip students with essential skills to analyze quantitative data and derive actionable insights for informed policy decisions. But what exactly is computational social science, and how can it be effectively integrated into the public policy curriculum? What methodologies and tools are crucial for leveraging data in policymaking? This blog post explores these questions and highlights the significance of computational social science in shaping effective public policy along with reference to the project currently underway at the Brandt School.
Understanding Computational Social Science
Computational social science is an interdisciplinary field that merges social science principles with computational methods to analyze complex social phenomena. The increase in computing power during the 1970s marked a significant turning point, as computers became more powerful and accessible to researchers. The development of statistical software and popular programming languages like R and Python in the 1990s started enabling social scientists to utilize computing power to explore social science enquiries. This enabled the analysis of larger societal datasets and facilitated more in-depth investigations. The emergence of Web 2.0 technologies in the early 2000s, along with online communication and social media platforms, started generating vast amounts of data. It is estimated that around 2.5 quintillion bytes are produced daily. This influx of information provided researchers with unprecedented opportunities to study human behavior on a large scale. However, it also necessitated the use of new computational methods capable of managing such vast volumes of data.
Over the past few years, there has been a noticeable shift in the methodologies emerging from peer-reviewed social science and policy journals. Social scientists and public policy researchers are increasingly employing new computational techniques, such as web scraping, data mining, and machine learning, to analyze social media interactions, public sentiment, online communities, network dynamics, and the spread of misinformation. This evolution is allowing researchers to uncover patterns and trends in large datasets, providing deeper insights into social dynamics and the impact of digital communication on society. Today, generative artificial intelligence and Large Language Models (LLMs) are further expanding these possibilities, allowing researchers to simulate complex social scenarios and derive insights that were previously unattainable.
In the context of public policy, computational social science provides a framework for analyzing the impact of policies, predicting outcomes, and evaluating the effectiveness of interventions. This approach enables researchers to make informed decisions based on empirical evidence rather than relying solely on subjective judgment or unverified observations.
The Essence of Computational Social Science and Data Analytics
The sheer volume of data produced today is staggering, influencing decision-making processes across sectors. Data has taken on a central position in every decision-making process, guiding policy communities in addressing pressing social issues. By employing advanced algorithms and simulation techniques on larger datasets, researchers uncover patterns and relationships that traditional methods may overlook. A recent example of this can be seen in how health and statistical bureaus around the world utilized computational methods during the COVID-19 pandemic in response to the public health emergency. In this context, data analytics serves as a crucial set of methods and tools for social scientists, aiding in the assessment of existing policies, the identification of emerging trends, and the prediction of the potential impact of new policies. This approach allows researchers to move beyond traditional qualitative methods, providing a more nuanced understanding of social issues. However, this does not undermine the value of qualitative methods; rather, data analytics complements qualitative approaches by offering additional insights and depth to the analysis.
Relevance for Public Policy Students
In recent years, public policy students have increasingly relied on data for their coursework and MA theses. They regularly explore databases from multilateral institutions such as the World Bank, European Union, and United Nations to analyze various policy indicators and historical data that inform their research and analysis. Common areas of inquiry for public policy students often include topics such as evaluating the effects of climate change, assessing the impact of infrastructure development, investigating the relationship between trade openness and economic growth, and evaluating the effectiveness of social protection programs or the impact of digitalization on the economy.
By analyzing data from diverse sources, data analytics facilitates the evaluation of existing programs and policies, allowing students to identify what works, what doesn’t, and why. This process encourages ongoing improvement in policy design and implementation. Fortunately, the Brandt School curriculum offers a comprehensive array of courses on statistical and economic analysis, as well as advanced methods. Given the rise of data-driven and evidence-informed policymaking, I have been reflecting on how to further support MPP students in a meaningful way by complementing our current courses by providing students with additional skills in data analytics. This approach can not only enhance their qualifications but also prepare them for the future job market.
Blended Learning Strategies for Effective Data Analytics in Public Policy
Motivated to introduce computational methods for social science inquiries, I initiated a project on computational social science in 2023 that received significant support through a state grant from the Thüringen Ministry of Science, Economics, and Digital Society (TMWWDG). This initiative is part of TMWWDG’s broader effort to promote innovation in digital higher education. By incentivizing the development of digitally supported teaching formats, the program aims to enhance the educational experience for students across disciplines.
A key aspect of the project is the development of new teaching modules on data analysis techniques and the application of machine learning tools like Python. By employing blended learning, the project aims to create digital teaching formats that facilitate year-round learning, ensuring that students have access to resources and support as they navigate the complexities of data analysis in public policy. Thanks to online learning platforms like Moodle, current and future students of the Brandt School will have the opportunity to access digital teaching modules on data analytics using Python at any time and at their own pace.
Teaching programming to non-technical and social science students can be a challenging task, especially for those with no prior programming background. However, this project is specifically designed for students with no programming background and employs blended learning methodologies, including live and recorded lectures, on-the-spot training, and group exercises. Moreover, by integrating each programming module with a social science perspective and following a capstone project approach, the learning of programming languages has become more engaging and relatable. This method allows students to see the practical applications of programming in real-world social science contexts, making the learning experience more meaningful. By working on projects that address actual policy issues, students can apply their technical skills to analyze data, draw conclusions, and propose evidence-based solutions.
To further encourage the practical application of the skills learned, students are also offered the chance to showcase their final projects by participating in a datathon. This event aims to promote a spirit of collaboration and competition while providing students with the opportunity to present their findings to peers and faculty, allowing them to receive valuable feedback.
About the Author

Dr. Hasnain Bokhari is a faculty member at the Brandt School and leads the Digitalization track. He currently serves as the principal investigator for the project on Computational Social Science in Public Policy. His research focuses on eGovernment, AI digital inclusion, the digital divide, and social media analytics. Additionally, he is an Associate Editor of the Journal of Entrepreneurship and Public Policy and holds a Ph.D. and an MA in Public Policy from the University of Erfurt.
~ The views represented in this blog post do not necessarily represent those of the Brandt School. ~
![[Translate to English:] Facebook Icon](/fileadmin/SocialMediaIcons/iconfinder_06-facebook_104498.svg "Fakebookseite der Staatswissenschaftlichen Fakultät")
![[Translate to English:] Youtube Icon](/fileadmin/SocialMediaIcons/iconfinder_18-youtube_104482.svg)


![[Translate to English:] facebook icon](/fileadmin/SocialMediaIcons/iconfinder_06-facebook_white.svg)
![[Translate to English:] twitter icon](/fileadmin/SocialMediaIcons/iconfinder_03-twitter_white.svg)
![[Translate to English:] instagram icon](/fileadmin/SocialMediaIcons/iconfinder_38-instagram_white.svg)
![[Translate to English:] YouTube icon](/fileadmin/SocialMediaIcons/iconfinder_18-youtube_white.svg)
![[Translate to English:] xing icon](/fileadmin/SocialMediaIcons/iconfinder_xing_white.svg)